Initial commit: LLM Wiki with raw and wiki folders only
This commit is contained in:
@@ -0,0 +1,224 @@
|
||||
---
|
||||
title: "Karpathy知识库「LLM Wiki」火爆了,全网围观讨论"
|
||||
source: "https://mp.weixin.qq.com/s/-2H3xFx_R4KIIZ_vDpEYQw"
|
||||
author:
|
||||
- "[[微信公众平台]]"
|
||||
published:
|
||||
created: 2026-04-07
|
||||
description: "一种新的知识构建方式"
|
||||
tags:
|
||||
- "clippings"
|
||||
rating: 4
|
||||
---
|
||||
*2026年4月5日 12:31*
|
||||
|
||||
机器之心编辑部
|
||||
|
||||
还记得前几天,AI 领域知名学者 Andrej Karpathy 做客一档节目时,半开玩笑地提到:token 用不完会让人焦虑,就像患上了某种「 [AI 精神病](https://mp.weixin.qq.com/s?__biz=MzA3MzI4MjgzMw==&mid=2651022949&idx=1&sn=9e4b21d9aaea56cfbc292f6031f251cc&scene=21#wechat_redirect) 」。
|
||||
|
||||
这句话当时听起来有点夸张,但当你仔细看他最近在做的一系列东西,会发现他确实在用 AI 不断试各种路径。
|
||||
|
||||
就在近日,Karpathy 构建的 LLM 知识库「LLM Wiki」爆火,在社区迅速传播,引发大量讨论。
|
||||
|
||||

|
||||
|
||||
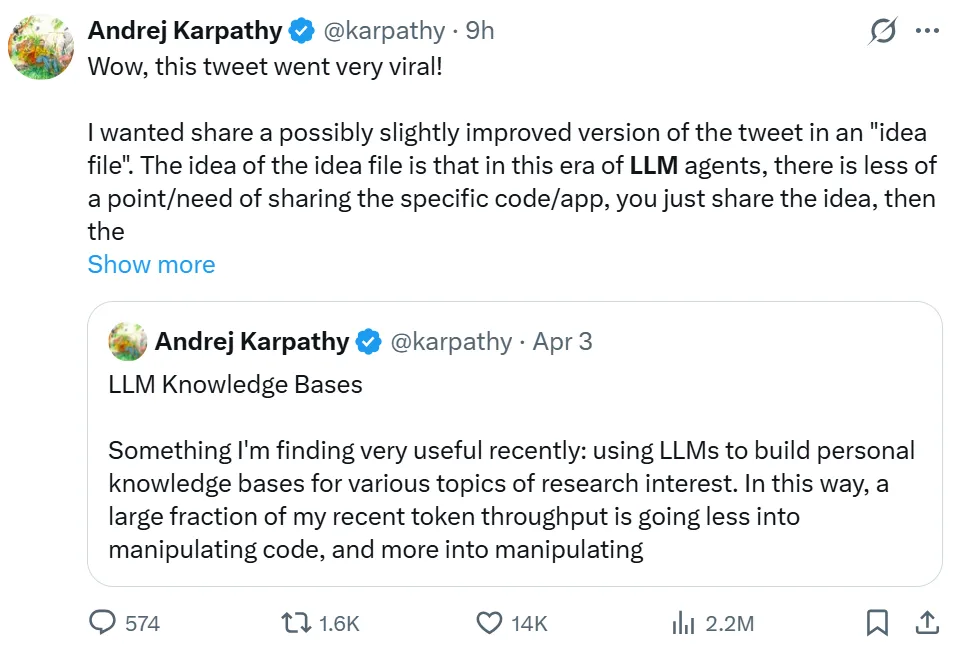
就连 Karpathy 自己都忍不住自夸一句:哇,我这条推文真的火爆了!
|
||||
|
||||
|
||||
|
||||
这条爆火的推文介绍了「LLM Wiki」的构建思路。Karpathy 表示,他把最近的想法稍微整理、优化了一下,然后用一个「idea file」的形式分享出来。在 LLM agent 时代,分享具体代码或应用的意义正在变弱,现在只需要分享想法,然后把它交给 Claude、Grok 等 Agent,它就可以根据你的需求,自动搭建一个属于你自己的个人知识库。
|
||||
|
||||
Karpathy 把这个想法整理成 gist 形式进行分发:你可以把它交给你的 agent,它会帮你构建一个属于你自己的 LLM wiki,并指导你如何使用等等。
|
||||
|
||||
' fill='%23FFFFFF'%3E%3Crect x='249' y='126' width='1' height='1'%3E%3C/rect%3E%3C/g%3E%3C/g%3E%3C/svg%3E)
|
||||
|
||||
地址:<https://gist.github.com/karpathy/442a6bf555914893e9891c11519de94f>
|
||||
|
||||
这个思路可以说是有点超前,在 Agent 时代,这意味着我们已经不需要再分享具体代码或应用了!只需要把「想法」交给对方的 Agent,让它根据你的需求自动完成定制和实现!
|
||||
|
||||
有观点认为,这不只是一个 AI 工具,而更像是一种元框架(meta-framework)。它并不依赖某个具体模型或技术栈,而是在尝试定义一种人类与 AI 协作管理知识的方式。随着模型不断迭代、框架持续演进,让 LLM 帮助编译并维护一个持续生长的 Wiki 这一模式,反而具备更长期的稳定性和适用性。
|
||||
|
||||
' fill='%23FFFFFF'%3E%3Crect x='249' y='126' width='1' height='1'%3E%3C/rect%3E%3C/g%3E%3C/g%3E%3C/svg%3E)
|
||||
|
||||
还有观点将这套「LLM Wiki」的工作方式梳理成一个更清晰的闭环,方便大家理解其核心逻辑:
|
||||
|
||||
- 将原始资料(论文 / 文章 / 代码 / 图片等)整理到 raw/ 目录中
|
||||
- 由 LLM 将其编译为一个结构化的 wiki(包含.md 文件、反向链接以及概念分类)
|
||||
- 使用 Obsidian 作为前端进行浏览
|
||||
- 当 wiki 达到一定规模(他的案例是:100 篇文章、40 万字)后,可以直接围绕整个 wiki 提出复杂问题
|
||||
- 将每一次问答的输出重新归档回 wiki—— 这一点我认为是核心;知识库会随着使用不断变强
|
||||
- 由 LLM 定期进行健康检查:发现矛盾数据、补全缺失信息、挖掘新的研究方向
|
||||
|
||||
在这一过程中,一个颇具启发性的判断是:在中等规模下,这套体系并不依赖传统意义上的 RAG。只要 LLM 能够维护好索引和摘要,就已经可以支撑起有效的检索与推理。
|
||||
|
||||
进一步看,这一思路的延伸方向也逐渐清晰,通过合成数据与微调,将知识逐步内化进模型权重,而不再仅仅依赖上下文窗口进行调用。
|
||||
|
||||
从这个角度来看,这已经不只是一个使用技巧,而是在逼近一种自我增强的知识系统形态,也可以被视为一个具备产品潜力的雏形。
|
||||
|
||||
' fill='%23FFFFFF'%3E%3Crect x='249' y='126' width='1' height='1'%3E%3C/rect%3E%3C/g%3E%3C/g%3E%3C/svg%3E)
|
||||
|
||||
为何要构建「LLM Wiki」
|
||||
|
||||
Karpathy 表示,大多数人使用 LLM 处理文档的方式,基本都类似于 RAG:你上传一组文件,模型在查询时检索相关片段,然后生成答案。
|
||||
|
||||
这种方式是有效的,但问题在于每一次提问,模型都在从零重新发现知识。没有积累。如果你问一个需要综合五篇文档的复杂问题,模型每次都要重新去找相关片段,再拼接起来。没有任何东西被沉淀下来。像 NotebookLM、ChatGPT 文件上传,以及大多数 RAG 系统,基本都是这种模式。
|
||||
|
||||
「LLM Wiki」提出的是一种不同的思路,不是在查询时直接从原始文档中检索,而是让 LLM 逐步构建并维护一个持续存在的 wiki,一个结构化、相互链接的 Markdown 文件集合,作为你和原始资料之间的中间层。
|
||||
|
||||
当你添加新的资料时,模型不只是简单地索引以备后用,而是会真正去阅读它,提取关键信息,并将其整合进现有的 wiki:更新实体页面、修订主题总结、标记新信息与旧结论之间的冲突,对整体认知进行强化或修正。知识被编译一次,并持续更新,而不是在每次查询时重新推导。
|
||||
|
||||
用 Karpathy 的话来说,这个 wiki 是一个持续存在、不断累积的产物。交叉引用已经提前建立,矛盾已经被标注,综合结论已经反映了你读过的所有内容。随着你不断加入新资料、提出新问题,这个 wiki 会持续变得更丰富。
|
||||
|
||||
你几乎不需要(或者很少需要)亲自去写这个 wiki,所有内容都由 LLM 来生成和维护。你负责的是提供资料、进行探索、提出问题;而模型负责所有苦活:总结、建立关联、归档整理、维护结构,让知识库随着时间真正变得有用。在实际使用中,通常是一边打开 LLM agent,一边打开 Obsidian:模型根据对话不断修改内容,而你可以实时浏览结果,点开链接、查看知识图谱、阅读更新后的页面。
|
||||
|
||||
这么说吧,Obsidian 是 IDE,LLM 是程序员,wiki 是代码库。
|
||||
|
||||
「LLM Wiki」是如何构建的?
|
||||
|
||||
这个系统可以分为三个层次:
|
||||
|
||||
原始数据:这是你整理好的原始资料集合,包括文章、论文、图片、数据文件等。这一层是不可变的:LLM 只读取它们,但不会对其进行任何修改,这是整个系统的事实来源。
|
||||
|
||||
Wiki 层(The wiki):一个由 LLM 生成的 Markdown 文件目录,包含摘要、实体页面、概念页面、对比分析、整体概览以及综合性总结等内容。这一层完全由 LLM 负责:它会创建页面,在新增资料时更新内容,维护交叉引用,并保证整体一致性。你负责阅读它;LLM 负责编写和维护它。
|
||||
|
||||
Schema 层(The schema):一份指导性文档(例如给 Claude Code 用的 CLAUDE.md,或给 Codex 用的 AGENTS.md),用于告诉 LLM:这个 wiki 的结构是什么、遵循哪些规范,以及在处理数据(ingest)、回答问题、维护内容时应采用什么样的工作流程。
|
||||
|
||||
这是整个系统的关键配置文件,正是它让 LLM 从一个通用聊天模型,变成一个有纪律的 wiki 维护者。随着你在具体领域中不断实践,这一层也会与你和 LLM 一起持续演化、不断优化。
|
||||
|
||||
操作(Operations)
|
||||
|
||||
数据摄取(Ingest):你将新的资料加入到原始数据集合中,并让 LLM 对其进行处理。一个典型流程是:LLM 读取资料,与你讨论关键要点,在 wiki 中写出一篇摘要页面,更新索引,同时更新整个 wiki 中相关的实体页和概念页,并在日志中追加一条记录。一个来源往往会影响 10–15 个 wiki 页面。Karpathy 个人更倾向于一次处理一个来源,并保持参与,他会阅读摘要、检查更新,并引导 LLM 强调重点。但你也可以选择批量导入多个来源,减少监督。最终,你可以形成一套适合自己风格的工作流,并将其记录在 schema 中,供后续使用。
|
||||
|
||||
查询(Query):你可以围绕 wiki 提出问题。LLM 会搜索相关页面,阅读内容,并综合生成带引用的回答。回答形式可以根据问题而变化,可以是一个 Markdown 页面、一个对比表、一份幻灯片(Marp)、一张图表(matplotlib),甚至是一个画布(canvas)。关键的一点是:好的回答可以被重新归档进 wiki,成为新的页面。无论是一次对比分析、一段推理,还是你发现的一条关联,这些内容都具有价值,不应该消失在聊天记录里。通过这种方式,你的探索会像导入的资料一样,在知识库中持续积累。
|
||||
|
||||
质量检查(Lint):可以定期让 LLM 对 wiki 进行健康检查。重点包括:页面之间是否存在矛盾;是否有被新资料取代的过时结论;是否存在没有入链的孤立页面;是否有被提及但尚未建立页面的重要概念;是否缺少交叉引用;是否存在可以通过网页搜索补充的数据空缺。LLM 也很擅长提出新的研究问题和建议新的信息来源。这一过程可以帮助 wiki 在不断扩展的同时,保持结构清晰和内容一致。
|
||||
|
||||
「LLM Wiki」应用场景
|
||||
|
||||
这种方式可以应用在很多不同场景中,例如:
|
||||
|
||||
个人层面:记录你的目标、健康、心理状态、自我成长过程,整理日记、文章、播客笔记,逐步构建一个关于你自己的结构化认知。
|
||||
|
||||
研究场景:围绕某个主题深入数周甚至数月,阅读论文、文章、报告,逐步构建一个不断演化的完整知识体系和核心观点。
|
||||
|
||||
读书场景:随着阅读进度整理每一章内容,建立人物、主题、情节线索之间的关联页面。读完之后,你会得到一个丰富的配套 wiki。可以类比像 Tolkien Gateway 这样的维基,由社区多年构建的、包含人物、地点、事件、语言等内容的庞大知识网络。现在,你可以在阅读过程中个人构建类似系统,由 LLM 完成所有的关联和维护。
|
||||
|
||||
企业 / 团队:一个由 LLM 维护的内部 wiki,持续接入 Slack 对话、会议记录、项目文档、客户沟通等信息,必要时由人工参与审核更新。由于维护工作由模型承担,这个 wiki 能够保持实时更新,而不再依赖团队成员额外投入精力。
|
||||
|
||||
竞品分析、尽职调查、旅行规划、课程笔记、兴趣深度研究,任何需要长期积累知识、并希望其被系统化组织而不是零散分布的场景,都可以采用这种模式。
|
||||
|
||||
最后,Karpathy 还强调了,关于「LLM Wiki」,他只是提供了一种思路,而不是一个具体实现。具体的目录结构、schema 规范、页面格式以及工具链,都会取决于用户使用场景、个人偏好以及所选择的 LLM。
|
||||
|
||||
上面提到的所有内容都是可选且模块化的,有用的就用,不合适的可以忽略。
|
||||
|
||||
' fill='%23FFFFFF'%3E%3Crect x='249' y='126' width='1' height='1'%3E%3C/rect%3E%3C/g%3E%3C/g%3E%3C/svg%3E)
|
||||
|
||||
© THE END
|
||||
|
||||
转载请联系本公众号获得授权
|
||||
|
||||
投稿或寻求报道:liyazhou@jiqizhixin.com
|
||||
|
||||
继续滑动看下一个
|
||||
|
||||
机器之心
|
||||
|
||||
向上滑动看下一个
|
||||
|
||||
搜索范围
|
||||
|
||||
全网
|
||||
|
||||
文库
|
||||
|
||||
学术
|
||||
|
||||
所有文献
|
||||
|
||||
所有文献
|
||||
|
||||
中文库
|
||||
|
||||
英文库
|
||||
|
||||
---
|
||||
|
||||
PubMed
|
||||
|
||||
北大核心
|
||||
|
||||
中科院分区
|
||||
|
||||
全部
|
||||
|
||||
---
|
||||
|
||||
中科院1区
|
||||
|
||||
中科院1-2区
|
||||
|
||||
中科院1-3区
|
||||
|
||||
JCR
|
||||
|
||||
全部
|
||||
|
||||
---
|
||||
|
||||
JCR:Q1
|
||||
|
||||
JCR:Q1-Q2
|
||||
|
||||
JCR:Q1-Q3
|
||||
|
||||
SCIE
|
||||
|
||||
EI
|
||||
|
||||
图片
|
||||
|
||||
视频
|
||||
|
||||
播客
|
||||
|
||||
我的
|
||||
|
||||
全部
|
||||
|
||||
我的
|
||||
|
||||
通识-持续更新
|
||||
|
||||
知识库obsidian
|
||||
|
||||
秘塔AI入门精选和使用技巧
|
||||
|
||||
AIforEDU
|
||||
|
||||
AI全栈提示词助手prompt专家
|
||||
|
||||
Download | Tailscale
|
||||
|
||||
营养师
|
||||
|
||||
芯片·半导体 行业全景库(持续更新)
|
||||
|
||||
慢成长图书馆(持续更新)
|
||||
|
||||
心灵工具箱
|
||||
|
||||
强度
|
||||
|
||||
深入
|
||||
|
||||
简洁
|
||||
|
||||
深入
|
||||
|
||||
深度研究
|
||||
|
||||
先想后搜
|
||||
|
||||
先搜后扩
|
||||
|
||||
科技新闻
|
||||
@@ -0,0 +1,87 @@
|
||||
---
|
||||
title: "llm-wiki"
|
||||
source: "https://gist.github.com/karpathy/442a6bf555914893e9891c11519de94f"
|
||||
author:
|
||||
- "[[Gist]]"
|
||||
published:
|
||||
created: 2026-04-07
|
||||
description: "llm-wiki. GitHub Gist: instantly share code, notes, and snippets."
|
||||
tags:
|
||||
- "clippings"
|
||||
rating: 4
|
||||
---
|
||||
|
||||
## LLM Wiki
|
||||
|
||||
A pattern for building personal knowledge bases using LLMs.
|
||||
|
||||
This is an idea file, it is designed to be copy pasted to your own LLM Agent (e.g. OpenAI Codex, Claude Code, OpenCode / Pi, or etc.). Its goal is to communicate the high level idea, but your agent will build out the specifics in collaboration with you.
|
||||
|
||||
## The core idea
|
||||
|
||||
Most people's experience with LLMs and documents looks like RAG: you upload a collection of files, the LLM retrieves relevant chunks at query time, and generates an answer. This works, but the LLM is rediscovering knowledge from scratch on every question. There's no accumulation. Ask a subtle question that requires synthesizing five documents, and the LLM has to find and piece together the relevant fragments every time. Nothing is built up. NotebookLM, ChatGPT file uploads, and most RAG systems work this way.
|
||||
|
||||
The idea here is different. Instead of just retrieving from raw documents at query time, the LLM **incrementally builds and maintains a persistent wiki** — a structured, interlinked collection of markdown files that sits between you and the raw sources. When you add a new source, the LLM doesn't just index it for later retrieval. It reads it, extracts the key information, and integrates it into the existing wiki — updating entity pages, revising topic summaries, noting where new data contradicts old claims, strengthening or challenging the evolving synthesis. The knowledge is compiled once and then *kept current*, not re-derived on every query.
|
||||
|
||||
This is the key difference: **the wiki is a persistent, compounding artifact.** The cross-references are already there. The contradictions have already been flagged. The synthesis already reflects everything you've read. The wiki keeps getting richer with every source you add and every question you ask.
|
||||
|
||||
You never (or rarely) write the wiki yourself — the LLM writes and maintains all of it. You're in charge of sourcing, exploration, and asking the right questions. The LLM does all the grunt work — the summarizing, cross-referencing, filing, and bookkeeping that makes a knowledge base actually useful over time. In practice, I have the LLM agent open on one side and Obsidian open on the other. The LLM makes edits based on our conversation, and I browse the results in real time — following links, checking the graph view, reading the updated pages. Obsidian is the IDE; the LLM is the programmer; the wiki is the codebase.
|
||||
|
||||
This can apply to a lot of different contexts. A few examples:
|
||||
|
||||
- **Personal**: tracking your own goals, health, psychology, self-improvement — filing journal entries, articles, podcast notes, and building up a structured picture of yourself over time.
|
||||
- **Research**: going deep on a topic over weeks or months — reading papers, articles, reports, and incrementally building a comprehensive wiki with an evolving thesis.
|
||||
- **Reading a book**: filing each chapter as you go, building out pages for characters, themes, plot threads, and how they connect. By the end you have a rich companion wiki. Think of fan wikis like [Tolkien Gateway](https://tolkiengateway.net/wiki/Main_Page) — thousands of interlinked pages covering characters, places, events, languages, built by a community of volunteers over years. You could build something like that personally as you read, with the LLM doing all the cross-referencing and maintenance.
|
||||
- **Business/team**: an internal wiki maintained by LLMs, fed by Slack threads, meeting transcripts, project documents, customer calls. Possibly with humans in the loop reviewing updates. The wiki stays current because the LLM does the maintenance that no one on the team wants to do.
|
||||
- **Competitive analysis, due diligence, trip planning, course notes, hobby deep-dives** — anything where you're accumulating knowledge over time and want it organized rather than scattered.
|
||||
|
||||
## Architecture
|
||||
|
||||
There are three layers:
|
||||
|
||||
**Raw sources** — your curated collection of source documents. Articles, papers, images, data files. These are immutable — the LLM reads from them but never modifies them. This is your source of truth.
|
||||
|
||||
**The wiki** — a directory of LLM-generated markdown files. Summaries, entity pages, concept pages, comparisons, an overview, a synthesis. The LLM owns this layer entirely. It creates pages, updates them when new sources arrive, maintains cross-references, and keeps everything consistent. You read it; the LLM writes it.
|
||||
|
||||
**The schema** — a document (e.g. CLAUDE.md for Claude Code or AGENTS.md for Codex) that tells the LLM how the wiki is structured, what the conventions are, and what workflows to follow when ingesting sources, answering questions, or maintaining the wiki. This is the key configuration file — it's what makes the LLM a disciplined wiki maintainer rather than a generic chatbot. You and the LLM co-evolve this over time as you figure out what works for your domain.
|
||||
|
||||
## Operations
|
||||
|
||||
**Ingest.** You drop a new source into the raw collection and tell the LLM to process it. An example flow: the LLM reads the source, discusses key takeaways with you, writes a summary page in the wiki, updates the index, updates relevant entity and concept pages across the wiki, and appends an entry to the log. A single source might touch 10-15 wiki pages. Personally I prefer to ingest sources one at a time and stay involved — I read the summaries, check the updates, and guide the LLM on what to emphasize. But you could also batch-ingest many sources at once with less supervision. It's up to you to develop the workflow that fits your style and document it in the schema for future sessions.
|
||||
|
||||
**Query.** You ask questions against the wiki. The LLM searches for relevant pages, reads them, and synthesizes an answer with citations. Answers can take different forms depending on the question — a markdown page, a comparison table, a slide deck (Marp), a chart (matplotlib), a canvas. The important insight: **good answers can be filed back into the wiki as new pages.** A comparison you asked for, an analysis, a connection you discovered — these are valuable and shouldn't disappear into chat history. This way your explorations compound in the knowledge base just like ingested sources do.
|
||||
|
||||
**Lint.** Periodically, ask the LLM to health-check the wiki. Look for: contradictions between pages, stale claims that newer sources have superseded, orphan pages with no inbound links, important concepts mentioned but lacking their own page, missing cross-references, data gaps that could be filled with a web search. The LLM is good at suggesting new questions to investigate and new sources to look for. This keeps the wiki healthy as it grows.
|
||||
|
||||
## Indexing and logging
|
||||
|
||||
Two special files help the LLM (and you) navigate the wiki as it grows. They serve different purposes:
|
||||
|
||||
**index.md** is content-oriented. It's a catalog of everything in the wiki — each page listed with a link, a one-line summary, and optionally metadata like date or source count. Organized by category (entities, concepts, sources, etc.). The LLM updates it on every ingest. When answering a query, the LLM reads the index first to find relevant pages, then drills into them. This works surprisingly well at moderate scale (~100 sources, ~hundreds of pages) and avoids the need for embedding-based RAG infrastructure.
|
||||
|
||||
**log.md** is chronological. It's an append-only record of what happened and when — ingests, queries, lint passes. A useful tip: if each entry starts with a consistent prefix (e.g. `## [2026-04-02] ingest | Article Title`), the log becomes parseable with simple unix tools — `grep "^## \[" log.md | tail -5` gives you the last 5 entries. The log gives you a timeline of the wiki's evolution and helps the LLM understand what's been done recently.
|
||||
|
||||
## Optional: CLI tools
|
||||
|
||||
At some point you may want to build small tools that help the LLM operate on the wiki more efficiently. A search engine over the wiki pages is the most obvious one — at small scale the index file is enough, but as the wiki grows you want proper search. [qmd](https://github.com/tobi/qmd) is a good option: it's a local search engine for markdown files with hybrid BM25/vector search and LLM re-ranking, all on-device. It has both a CLI (so the LLM can shell out to it) and an MCP server (so the LLM can use it as a native tool). You could also build something simpler yourself — the LLM can help you vibe-code a naive search script as the need arises.
|
||||
|
||||
## Tips and tricks
|
||||
|
||||
- **Obsidian Web Clipper** is a browser extension that converts web articles to markdown. Very useful for quickly getting sources into your raw collection.
|
||||
- **Download images locally.** In Obsidian Settings → Files and links, set "Attachment folder path" to a fixed directory (e.g. `raw/assets/`). Then in Settings → Hotkeys, search for "Download" to find "Download attachments for current file" and bind it to a hotkey (e.g. Ctrl+Shift+D). After clipping an article, hit the hotkey and all images get downloaded to local disk. This is optional but useful — it lets the LLM view and reference images directly instead of relying on URLs that may break. Note that LLMs can't natively read markdown with inline images in one pass — the workaround is to have the LLM read the text first, then view some or all of the referenced images separately to gain additional context. It's a bit clunky but works well enough.
|
||||
- **Obsidian's graph view** is the best way to see the shape of your wiki — what's connected to what, which pages are hubs, which are orphans.
|
||||
- **Marp** is a markdown-based slide deck format. Obsidian has a plugin for it. Useful for generating presentations directly from wiki content.
|
||||
- **Dataview** is an Obsidian plugin that runs queries over page frontmatter. If your LLM adds YAML frontmatter to wiki pages (tags, dates, source counts), Dataview can generate dynamic tables and lists.
|
||||
- The wiki is just a git repo of markdown files. You get version history, branching, and collaboration for free.
|
||||
|
||||
## Why this works
|
||||
|
||||
The tedious part of maintaining a knowledge base is not the reading or the thinking — it's the bookkeeping. Updating cross-references, keeping summaries current, noting when new data contradicts old claims, maintaining consistency across dozens of pages. Humans abandon wikis because the maintenance burden grows faster than the value. LLMs don't get bored, don't forget to update a cross-reference, and can touch 15 files in one pass. The wiki stays maintained because the cost of maintenance is near zero.
|
||||
|
||||
The human's job is to curate sources, direct the analysis, ask good questions, and think about what it all means. The LLM's job is everything else.
|
||||
|
||||
The idea is related in spirit to Vannevar Bush's Memex (1945) — a personal, curated knowledge store with associative trails between documents. Bush's vision was closer to this than to what the web became: private, actively curated, with the connections between documents as valuable as the documents themselves. The part he couldn't solve was who does the maintenance. The LLM handles that.
|
||||
|
||||
## Note
|
||||
|
||||
This document is intentionally abstract. It describes the idea, not a specific implementation. The exact directory structure, the schema conventions, the page formats, the tooling — all of that will depend on your domain, your preferences, and your LLM of choice. Everything mentioned above is optional and modular — pick what's useful, ignore what isn't. For example: your sources might be text-only, so you don't need image handling at all. Your wiki might be small enough that the index file is all you need, no search engine required. You might not care about slide decks and just want markdown pages. You might want a completely different set of output formats. The right way to use this is to share it with your LLM agent and work together to instantiate a version that fits your needs. The document's only job is to communicate the pattern. Your LLM can figure out the rest.
|
||||
@@ -0,0 +1,282 @@
|
||||
---
|
||||
title: "Marp 学习资料汇编"
|
||||
source:
|
||||
- "https://github.com/marp-team/marp"
|
||||
- "https://github.com/marp-team/marpit"
|
||||
- "https://github.com/marp-team/marp-cli"
|
||||
- "https://github.com/JichouP/obsidian-marp-plugin"
|
||||
- "https://samuele-cozzi.github.io/obsidian-marp-slides/"
|
||||
author:
|
||||
- "[[Marp Team]]"
|
||||
- "[[JichouP]]"
|
||||
- "[[Samuele Cozzi]]"
|
||||
created: 2026-04-07
|
||||
description: "Marp 生态系统学习资料汇编:Marpit 框架、Marp CLI、Obsidian Marp 插件"
|
||||
tags:
|
||||
- "clippings"
|
||||
- "marp"
|
||||
- "presentation"
|
||||
- "obsidian"
|
||||
rating: 4
|
||||
---
|
||||
|
||||
## 1. Marp 生态系统概述
|
||||
|
||||
Marp 是一个用纯 Markdown 编写演示文稿的生态系统。
|
||||
|
||||
核心组件:
|
||||
|
||||
| 组件 | 说明 |
|
||||
|------|------|
|
||||
| **Marpit** | 瘦框架,将 Markdown 转为幻灯片 |
|
||||
| **Marp Core** | 核心转换引擎,含内置主题 |
|
||||
| **Marp CLI** | 命令行工具,导出 HTML/PDF/PPTX/图片 |
|
||||
| **Marp for VS Code** | VS Code 扩展,实时预览 |
|
||||
| **Obsidian Marp Plugin** | Obsidian 集成,预览和导出 |
|
||||
|
||||
---
|
||||
|
||||
## 2. Marpit 指令系统(Directives)
|
||||
|
||||
Marpit 通过"指令"扩展 Markdown,控制幻灯片的行为和样式。
|
||||
|
||||
### 写法
|
||||
|
||||
**HTML 注释方式**:
|
||||
|
||||
```markdown
|
||||
<!--
|
||||
theme: default
|
||||
paginate: true
|
||||
-->
|
||||
```
|
||||
|
||||
**Front-matter 方式**:
|
||||
|
||||
```markdown
|
||||
---
|
||||
theme: default
|
||||
paginate: true
|
||||
---
|
||||
```
|
||||
|
||||
### 全局指令(Global Directives)
|
||||
|
||||
作用于整个演示文稿,多次书写只认最后一个。
|
||||
|
||||
| 指令 | 说明 |
|
||||
|------|------|
|
||||
| `theme` | 指定主题 |
|
||||
| `style` | 自定义 CSS(避免污染其他编辑器) |
|
||||
| `headingDivider` | 按标题级别自动分页 |
|
||||
| `lang` | 设置 HTML lang 属性 |
|
||||
|
||||
### 局部指令(Local Directives)
|
||||
|
||||
作用于**当前页及后续所有页**。
|
||||
|
||||
| 指令 | 说明 |
|
||||
|------|------|
|
||||
| `paginate` | 显示页码(true/false/hold/skip) |
|
||||
| `header` | 页眉内容 |
|
||||
| `footer` | 页脚内容 |
|
||||
| `class` | 设置 `<section>` 的 CSS 类 |
|
||||
| `backgroundColor` | 背景色 |
|
||||
| `backgroundImage` | 背景图 |
|
||||
| `backgroundPosition` | 背景位置(默认 center) |
|
||||
| `backgroundRepeat` | 背景重复(默认 no-repeat) |
|
||||
| `backgroundSize` | 背景大小(默认 cover) |
|
||||
| `color` | 文字颜色 |
|
||||
|
||||
### Spot 指令(仅当前页)
|
||||
|
||||
在局部指令名前加 `_` 前缀,仅对当前页生效:
|
||||
|
||||
```markdown
|
||||
<!-- _backgroundColor: black -->
|
||||
<!-- _color: white -->
|
||||
```
|
||||
|
||||
### 分页控制(paginate 的四种值)
|
||||
|
||||
| 值 | 显示页码 | 递增页码 |
|
||||
|----|----------|----------|
|
||||
| `true` | ✅ | ✅ |
|
||||
| `false` | ❌ | ✅ |
|
||||
| `hold` | ✅ | ❌ |
|
||||
| `skip` | ❌ | ❌ |
|
||||
|
||||
### 标题自动分页(headingDivider)
|
||||
|
||||
```markdown
|
||||
<!-- headingDivider: 2 -->
|
||||
|
||||
# 1st page
|
||||
内容...
|
||||
|
||||
## 2nd page(h2 触发分页)
|
||||
内容...
|
||||
|
||||
# 3rd page(h1 也触发分页)
|
||||
```
|
||||
|
||||
数值表示"大于等于该级别的标题都会分页",数组则只对指定级别生效。
|
||||
|
||||
---
|
||||
|
||||
## 3. 内置主题
|
||||
|
||||
Marp Core 提供三个内置主题:
|
||||
|
||||
| 主题 | 风格 |
|
||||
|------|------|
|
||||
| `default` | 经典白底,蓝灰色调 |
|
||||
| `uncover` | 现代、极简、居中布局 |
|
||||
| `gaia` | 彩色、大胆、左对齐 |
|
||||
|
||||
使用方式:
|
||||
|
||||
```markdown
|
||||
---
|
||||
marp: true
|
||||
theme: uncover
|
||||
---
|
||||
```
|
||||
|
||||
### 自定义主题
|
||||
|
||||
创建 CSS 文件,使用 Marpit 的主题规范:
|
||||
|
||||
```css
|
||||
/* @theme my-theme */
|
||||
@import 'default';
|
||||
|
||||
section {
|
||||
background-color: #f5f5f5;
|
||||
color: #333;
|
||||
}
|
||||
|
||||
h1 {
|
||||
color: #0066cc;
|
||||
}
|
||||
```
|
||||
|
||||
---
|
||||
|
||||
## 4. Marp CLI
|
||||
|
||||
### 安装
|
||||
|
||||
```bash
|
||||
# npm
|
||||
npx @marp-team/marp-cli@latest
|
||||
|
||||
# macOS
|
||||
brew install marp-cli
|
||||
|
||||
# Windows (Scoop)
|
||||
scoop install marp
|
||||
```
|
||||
|
||||
### 基本用法
|
||||
|
||||
```bash
|
||||
# 导出 HTML(默认)
|
||||
marp presentation.md
|
||||
|
||||
# 导出 PDF
|
||||
marp presentation.md --pdf
|
||||
|
||||
# 导出 PPTX
|
||||
marp presentation.md --pptx
|
||||
|
||||
# 指定输出文件
|
||||
marp presentation.md -o output.html
|
||||
|
||||
# 使用特定主题
|
||||
marp --theme uncover --pdf presentation.md
|
||||
|
||||
# 导出后立即打开
|
||||
marp presentation.md --pdf --open
|
||||
```
|
||||
|
||||
> PDF/PPTX 导出需要系统安装 Chrome 或 Edge。
|
||||
|
||||
---
|
||||
|
||||
## 5. Obsidian Marp 插件
|
||||
|
||||
来源:<https://github.com/JichouP/obsidian-marp-plugin>
|
||||
|
||||
### 功能
|
||||
|
||||
- **预览**:点击侧边栏按钮或命令面板运行 `Marp: Open Preview`
|
||||
- **自动重载**:保存文件后自动刷新预览
|
||||
- **导出**:支持 PDF、PPTX、HTML(需要 Node.js)
|
||||
- **图片嵌入**:支持 Wikilink(`![[image.png]]`)和 CommonMark(``)格式
|
||||
- **过渡效果**:HTML 导出支持页面过渡动画
|
||||
|
||||
### 设置
|
||||
|
||||
| 设置项 | 类型 | 默认值 | 说明 |
|
||||
|--------|------|--------|------|
|
||||
| Enable Auto Reload | toggle | on | 保存时自动刷新预览 |
|
||||
| Open Preview in Split Tab | toggle | on | 在分栏中打开预览 |
|
||||
| Theme Folder Location | text | `MarpTheme` | 自定义主题 CSS 目录 |
|
||||
|
||||
### 自定义主题
|
||||
|
||||
```
|
||||
<your-vault>
|
||||
└── MarpTheme/
|
||||
├── beamer.css
|
||||
├── border.css
|
||||
└── gradient.css
|
||||
```
|
||||
|
||||
> 添加 CSS 后需要重启 Obsidian。
|
||||
|
||||
### 图片处理
|
||||
|
||||
导出时图片自动转为 Base64 嵌入,支持本地图片分享。路径支持:
|
||||
|
||||
- Wikilink:`![[path/to/image.png]]`
|
||||
- CommonMark:``
|
||||
- 绝对路径和相对路径(相对于 vault 根目录)
|
||||
|
||||
---
|
||||
|
||||
## 6. 最小可运行示例
|
||||
|
||||
```markdown
|
||||
---
|
||||
marp: true
|
||||
theme: uncover
|
||||
paginate: true
|
||||
---
|
||||
|
||||
# 我的第一个 Marp 幻灯片
|
||||
|
||||
用 Markdown 写演示文稿
|
||||
|
||||
---
|
||||
|
||||
## 第二页
|
||||
|
||||
- 项目一
|
||||
- 项目二
|
||||
- 项目三
|
||||
|
||||
---
|
||||
|
||||
## 第三页
|
||||
|
||||
> 就这么简单!
|
||||
|
||||
<!-- _backgroundColor: #1a1a2e -->
|
||||
<!-- _color: #e0e0e0 -->
|
||||
|
||||
# 深色背景页
|
||||
|
||||
这段文字是浅色的
|
||||
```
|
||||
@@ -0,0 +1,68 @@
|
||||
---
|
||||
title: "Marp CSS 主题推荐"
|
||||
source:
|
||||
- "https://github.com/favourhong/Awesome-Marp"
|
||||
- "https://github.com/cunhapaulo/marpstyle"
|
||||
- "https://github.com/rnd195/marp-community-themes"
|
||||
- "https://github.com/zhaoluting/marp-themes"
|
||||
- "https://github.com/cunhapaulo/MarpX"
|
||||
- "https://github.com/marp-team/awesome-marp"
|
||||
author:
|
||||
- "[[favourhong]]"
|
||||
- "[[cunhapaulo]]"
|
||||
- "[[rnd195]]"
|
||||
- "[[zhaoluting]]"
|
||||
created: 2026-04-07
|
||||
description: "GitHub 上优质的 Marp CSS 主题合集推荐"
|
||||
tags:
|
||||
- "clippings"
|
||||
- "marp"
|
||||
- "themes"
|
||||
- "css"
|
||||
rating: 4
|
||||
---
|
||||
|
||||
## 1. favourhong/Awesome-Marp ⭐953
|
||||
|
||||
最全面的中文友好学术主题,直接对标 LaTeX Beamer。
|
||||
|
||||
- 6 种主题色:深色、绿色、蓝色、红色、紫色、棕色
|
||||
- 38 种自定义样式:页面分栏(8种)、列表分栏(6种)、封面页(5种)、目录页(3种)、Callout(5种)、导航进度栏
|
||||
- 中文字体适配:方正宋刻本秀楷、方正苏新诗柳楷、霞鹜文楷
|
||||
- 搭配 VS Code 或 Obsidian 使用
|
||||
- 仓库:<https://github.com/favourhong/Awesome-Marp>
|
||||
|
||||
核心结构:themes/ 下 6 个 SCSS 文件,通过 CSS 变量控制主题色,class 指令切换布局。
|
||||
|
||||
## 2. cunhapaulo/marpstyle ⭐198
|
||||
|
||||
简洁美观的通用主题合集。
|
||||
|
||||
- 注重美感和简洁
|
||||
- MIT 开源
|
||||
- 仓库:<https://github.com/cunhapaulo/marpstyle>
|
||||
|
||||
升级版 MarpX(⭐62):<https://github.com/cunhapaulo/MarpX>
|
||||
|
||||
## 3. rnd195/marp-community-themes ⭐42
|
||||
|
||||
社区维护的主题画廊,有在线预览。
|
||||
|
||||
- 在线预览:<https://rnd195.github.io/marp-community-themes/>
|
||||
- 10 个主题含明暗分类
|
||||
- 包括:Academic、Beam、Border、Gradient、Graph Paper、Rosé Pine 系列(Dawn/Moon)、Gaia、Uncover
|
||||
- 仓库:<https://github.com/rnd195/marp-community-themes>
|
||||
|
||||
## 4. zhaoluting/marp-themes ⭐79
|
||||
|
||||
机构定制主题示例。
|
||||
|
||||
- 公司浅蓝主题
|
||||
- 浙大蓝学术主题
|
||||
- 仓库:<https://github.com/zhaoluting/marp-themes>
|
||||
|
||||
## 5. marp-team/awesome-marp
|
||||
|
||||
官方 awesome list,汇总生态工具和主题。
|
||||
|
||||
- 仓库:<https://github.com/marp-team/awesome-marp>
|
||||
@@ -0,0 +1,372 @@
|
||||
---
|
||||
title: "刚刚,Karpathy 开源个人 LLM Wiki"
|
||||
source: "https://mp.weixin.qq.com/s/vYVx8yf9eoTGXSWIrpOZ6Q"
|
||||
author:
|
||||
- "[[J0hn]]"
|
||||
published:
|
||||
created: 2026-04-07
|
||||
description: "不是代码,是一份 75 行的「idea file」,丢给你的 Agent 就能跑。"
|
||||
tags:
|
||||
- "clippings"
|
||||
rating: 4
|
||||
---
|
||||
|
||||
原创 J0hn *2026年4月5日 09:01*
|
||||
|
||||
Karpathy 的一条帖子,3 天拿下 4.3 万点赞、1200 万浏览,直接炸了。
|
||||
|
||||
 
|
||||
|
||||
两天前,Karpathy 在 X 上发了一条长帖,标题是: **LLM Knowledge Bases** 。
|
||||
|
||||
他说自己最近花在 LLM 上的 token,越来越少用来写代码了,更多是在「操控知识」。
|
||||
|
||||
> “ 我最近发现了一个非常有用的东西:用 LLM 来为各种研究兴趣构建个人知识库。这样一来,我最近的 token 消耗中,有很大一部分不再是用来操控代码,而是用来操控知识(以 Markdown 和图片的形式存储)。
|
||||
|
||||
两天后,他把这套方法论写成了一份 gist 发到 GitHub 上,开源给所有人。
|
||||
|
||||
' fill='%23FFFFFF'%3E%3Crect x='249' y='126' width='1' height='1'%3E%3C/rect%3E%3C/g%3E%3C/g%3E%3C/svg%3E)
|
||||
|
||||
但这份开源,跟以往的不太一样。
|
||||
|
||||
01
|
||||
|
||||
## 不是代码,是想法
|
||||
|
||||
Karpathy 这次开源的不是一个 repo,不是一个框架,甚至不是一段脚本。
|
||||
|
||||
' fill='%23FFFFFF'%3E%3Crect x='249' y='126' width='1' height='1'%3E%3C/rect%3E%3C/g%3E%3C/g%3E%3C/svg%3E)
|
||||
|
||||
是一份……75 行的 Markdown 文件,他叫它 **idea file** 。
|
||||
|
||||
Karpathy 说:
|
||||
|
||||
> “ 在这个 LLM Agent 的时代,分享具体的代码或应用已经意义不大了。你只需要分享想法,然后对方的 Agent 会根据你的具体需求来定制和构建。
|
||||
|
||||
你可以把这份文件直接丢给 Claude Code、OpenAI Codex 或者任何你喜欢的 Agent,它就能帮你搭建出你自己的 LLM Wiki,并指导你怎么用。
|
||||
|
||||
' fill='%23FFFFFF'%3E%3Crect x='249' y='126' width='1' height='1'%3E%3C/rect%3E%3C/g%3E%3C/g%3E%3C/svg%3E)
|
||||
|
||||
换句话说: **开源的不再是代码,而是思路。**
|
||||
|
||||
造词大师 Karpathy 还顺便又造了个新词。
|
||||
|
||||
有人在评论区回复他,他提到 Peter Steinberger 跟他说,以后 PR 应该叫 **Prompt Request** ,而不是 Pull Request。因为 Agent 完全有能力自己实现大多数想法,没必要把你的想法用免费版 ChatGPT 写成一坨 vibe coding 的代码再提交。
|
||||
|
||||
02
|
||||
|
||||
## 所以到底是啥
|
||||
|
||||
简单来说,Karpathy 搞了一套系统:让 LLM 帮你把乱七八糟的资料「编译」成一个结构清晰、互相链接的 Markdown Wiki。
|
||||
|
||||
传统的 RAG 大家都知道:你上传一堆文件,LLM 每次提问时去检索相关片段,然后生成答案。NotebookLM、ChatGPT 文件上传,基本都是这个思路。
|
||||
|
||||
问题在哪呢? **每次提问,LLM 都在从头发现知识。没有积累。**
|
||||
|
||||
' fill='%23FFFFFF'%3E%3Crect x='249' y='126' width='1' height='1'%3E%3C/rect%3E%3C/g%3E%3C/g%3E%3C/svg%3E)
|
||||
|
||||
RAG 每次从头来 vs LLM Wiki 知识持续积累
|
||||
|
||||
Karpathy 的做法不同。
|
||||
|
||||
他让 LLM 读完原始资料后,不只是建索引等着被查询,而是主动把关键信息提取出来,整合到一个持续维护的 Wiki 里:更新实体页面、修订主题摘要、标注新旧数据之间的矛盾、不断强化已有的综合分析。
|
||||
|
||||
**知识被「编译」一次之后,就持续保鲜,而不是每次查询都重新推导。**
|
||||
|
||||
这就像把你的研究资料交给一位全职的图书管理员,他不会忘记更新交叉引用,不会厌烦琐碎的整理工作,一次操作就能同时修改 15 个文件。
|
||||
|
||||
03
|
||||
|
||||
## 三层架构
|
||||
|
||||
' fill='%23FFFFFF'%3E%3Crect x='249' y='126' width='1' height='1'%3E%3C/rect%3E%3C/g%3E%3C/g%3E%3C/svg%3E)
|
||||
|
||||
LLM Wiki 三层架构
|
||||
|
||||
LLM Wiki 三层架构
|
||||
|
||||
**原始资料层** ,也就是 `raw/` 目录。文章、论文、图片、数据集,统统往里扔。这一层是只读的,LLM 只看不改。
|
||||
|
||||
**Wiki 层** ,一堆 LLM 生成的 Markdown 文件。摘要、实体页、概念页、对比分析、综述。全部由 LLM 自动创建和维护,你只负责阅读。
|
||||
|
||||
**Schema 层** ,一个配置文件(比如 Claude Code 的 CLAUDE.md)。它告诉 LLM 这个 Wiki 怎么组织、遵循什么规范、遇到不同操作该走什么流程。 **这是把 LLM 从通用聊天机器人变成专业 Wiki 维护者的关键。**
|
||||
|
||||
04
|
||||
|
||||
## 怎么跑
|
||||
|
||||
日常使用主要是三个操作:
|
||||
|
||||
**灌入** 。把新资料丢进 raw/ 目录,告诉 LLM 去处理。LLM 读完之后会跟你讨论要点,写一页摘要,更新索引,然后跑去更新 Wiki 里所有相关的实体页和概念页。一份资料可能会触发 10 到 15 个页面的更新。
|
||||
|
||||
**提问** 。向 Wiki 提问。LLM 会搜索相关页面,读完之后综合出一个带引用的回答。回答可以是 Markdown、对比表格、Marp 幻灯片、matplotlib 图表,各种格式都行。关键的一步是: **好的回答可以被归档回 Wiki,变成新的页面。** 你的每一次探索,都在给知识库「添砖加瓦」。
|
||||
|
||||
**巡检** 。定期让 LLM 对 Wiki 做一次「体检」:找矛盾、补缺失、发现新的关联、标记需要深入研究的方向。LLM 还挺擅长给你出下一步的研究题目。
|
||||
|
||||
' fill='%23FFFFFF'%3E%3Crect x='249' y='126' width='1' height='1'%3E%3C/rect%3E%3C/g%3E%3C/g%3E%3C/svg%3E)
|
||||
|
||||
灌入、提问、巡检的知识循环
|
||||
|
||||
Karpathy 说自己平时就是一边开着 LLM Agent,一边开着 Obsidian。LLM 在对话中做编辑,他在 Obsidian 里实时看结果,点链接、翻图谱、读更新后的页面。
|
||||
|
||||
> “ Obsidian 是 IDE,LLM 是程序员,Wiki 是代码库。
|
||||
|
||||
他在一个研究方向上积累了大约 **100 篇文章、40 万字** 。本来以为得上花哨的 RAG 方案,结果……LLM 自己维护索引文件和文档摘要就够了,在这个规模下查什么都算顺畅。
|
||||
|
||||
05
|
||||
|
||||
## 评论区
|
||||
|
||||
这条帖子的评论区也是相当热闹和优质,Karpathy 自己就回了几十条。
|
||||
|
||||
有人问怎么用它来读书。Karpathy 的建议是:用 epub 格式而不是 PDF,一章一章地喂给 LLM,让它边读边整理。
|
||||
|
||||
> “ 别指望把一个 PDF 丢进去就让它总结,得「慢慢来」,一块一块地处理。当我分阶段做的时候,结果好得不得了,已经离不开了。
|
||||
|
||||
还有人问他底层用了什么技术栈。答案是:就是一个嵌套目录,里面是 `.md` 文件和 `.png` 图片,再加几个 `.csv` 和 `.py` ,Schema 写在 AGENTS.md 里。
|
||||
|
||||
没有数据库,没有框架。
|
||||
|
||||
Karpathy 还补了一个操作细节:他目前是手动添加每一份资料的,一份一份来,全程在线参与。等 LLM「学会」了这个 Wiki 的模式之后,后面再加新文档就轻松了,只需要说一句「把这份新文档归档到我们的 Wiki:(路径)」就行。
|
||||
|
||||
Obsidian 的创始人 Steph Ango 也在评论区出现了,提出了一个叫「Contamination Mitigation」的概念:建议把个人的笔记库和 Agent 的工作区分开,让 Agent 在一个「乱一点的」空间里折腾,整理好的成果再搬回你的主库。Karpathy 对此表示认同,他的 raw/ 目录就是起这个作用的。
|
||||
|
||||
有人问他会不会出个视频教程。Karpathy 说:
|
||||
|
||||
> “ 我刚好也在想这个。
|
||||
|
||||
06
|
||||
|
||||
## Farzapedia
|
||||
|
||||
Karpathy 帖子炸了之后两天,一个叫 Farza 的开发者就搞出了一个让人眼前一亮的实践。
|
||||
|
||||
' fill='%23FFFFFF'%3E%3Crect x='249' y='126' width='1' height='1'%3E%3C/rect%3E%3C/g%3E%3C/g%3E%3C/svg%3E)
|
||||
|
||||
Farza 的 Farzapedia 演示
|
||||
|
||||
Farza 让 LLM 从他的 2500 条日记、Apple Notes 和一些 iMessage 对话中,生成了一个 **关于他自己的个人维基百科** 。
|
||||
|
||||
' fill='%23FFFFFF'%3E%3Crect x='249' y='126' width='1' height='1'%3E%3C/rect%3E%3C/g%3E%3C/g%3E%3C/svg%3E)
|
||||
|
||||
这个 Wiki 包含 400 篇详细文章,涵盖了他的朋友、创业项目、研究方向,甚至他最喜欢的动漫以及这些动漫对他的影响,全部带有反向链接。
|
||||
|
||||
' fill='%23FFFFFF'%3E%3Crect x='249' y='126' width='1' height='1'%3E%3C/rect%3E%3C/g%3E%3C/g%3E%3C/svg%3E)
|
||||
|
||||
Farzapedia 个人知识百科的工作流程
|
||||
|
||||
注意,关键在于:
|
||||
|
||||
> “ 这个 Wiki 不是给我看的,是给我的 Agent 看的。
|
||||
|
||||
Wiki 的文件结构和反向链接对任何 Agent 来说都非常容易爬取。他可以在 Wiki 上启动 Claude Code,Agent 从 index.md 出发,就能精准定位到需要的页面。
|
||||
|
||||
举个例子:Farza 在设计新的落地页时,跟 Agent 说「看看最近启发我的图片和电影,给我一些文案和视觉风格的建议」。
|
||||
|
||||
Agent 就自己跑去翻他的 Wiki,拉出了吉卜力纪录片的笔记、YC 公司落地页的截图,甚至是他几年前保存的 1970 年代甲壳虫乐队周边的照片,然后给出了一个相当靠谱的回答。
|
||||
|
||||
Farza 说他一年前用 RAG 做过类似的系统,但效果一言难尽。而基于文件系统的知识库,Agent 天然就能理解,反而好用得多。
|
||||
|
||||
07
|
||||
|
||||
## Karpathy 点赞
|
||||
|
||||
Karpathy 看到 Farzapedia 之后专门发了一条帖子,列出了这种方式做 AI 个性化的四个优势:
|
||||
|
||||
' fill='%23FFFFFF'%3E%3Crect x='249' y='126' width='1' height='1'%3E%3C/rect%3E%3C/g%3E%3C/g%3E%3C/svg%3E)
|
||||
|
||||
**可见。** 记忆不是藏在模型里面的黑箱。它就是一个 Wiki,你能看到 AI 知道什么、不知道什么,能检查、能管理。
|
||||
|
||||
**你自己的。** 数据在你本地电脑上,不在某个 AI 公司的系统里。你对自己的信息有完全的控制权。
|
||||
|
||||
**文件优先。** 知识库就是一堆通用格式的文件:Markdown 和图片。这意味着数据可以互操作,你可以用 Unix 工具链、任何 CLI 来处理它们。想用 Obsidian 看就用 Obsidian,想自己写个界面也行。
|
||||
|
||||
**BYOAI(自带 AI)。** 你可以用 Claude、Codex、OpenCode 或任何你喜欢的 AI 来接入这些数据。甚至可以考虑用开源模型在你的 Wiki 上做微调,让 AI 把关于你的知识「编进」模型权重里。
|
||||
|
||||
' fill='%23FFFFFF'%3E%3Crect x='249' y='126' width='1' height='1'%3E%3C/rect%3E%3C/g%3E%3C/g%3E%3C/svg%3E)
|
||||
|
||||
Karpathy 还总结道:
|
||||
|
||||
> “ 这种个性化方式把控制权完全交到你手上。数据是你的,格式是通用的,内容是可检查的。用哪个 AI 随你,让 AI 公司们卷起来吧。
|
||||
|
||||
08
|
||||
|
||||
## 一个 80 年前的梦
|
||||
|
||||
Karpathy 在 gist 里提到了一段 81 年前的往事。
|
||||
|
||||
1945 年,Vannevar Bush 提出了 **Memex** 的概念:一个私人的、经过整理的知识库,文档之间有关联性的「踪迹」相互连接。Bush 的愿景其实比后来的万维网更接近 Karpathy 现在做的事情:私密的、主动整理的、文档之间的连接和文档本身同样重要。
|
||||
|
||||
**Bush 没能解决的问题是:谁来做维护?**
|
||||
|
||||
81 年后……答案来了:LLM。
|
||||
|
||||
它不会忘记更新交叉引用,不会觉得整理工作无聊,一次操作就能触及几十个文件。Wiki 能持续保持更新,因为维护的成本趋近于零。
|
||||
|
||||
09
|
||||
|
||||
## 从 vibe coding 到知识编译
|
||||
|
||||
回头看 Karpathy 这两年的轨迹,能看到一条清晰的演进线:
|
||||
|
||||
2025 年 2 月,他造了 **vibe coding** 这个词,意思是写代码的时候完全「跟着感觉走」,让 AI 写,自己不看。
|
||||
|
||||
2025 年底,他提出了 **Agentic Engineering** ,用 AI Agent 来写代码,但加上了人类的监督和审查。
|
||||
|
||||
2026 年 4 月,LLM Knowledge Bases。这回 LLM 操控的……不再是代码,而是知识本身了。
|
||||
|
||||
' fill='%23FFFFFF'%3E%3Crect x='249' y='126' width='1' height='1'%3E%3C/rect%3E%3C/g%3E%3C/g%3E%3C/svg%3E)
|
||||
|
||||
Karpathy 的思想进化路线
|
||||
|
||||
**Markdown 正在成为 AI 时代的编程语言。**
|
||||
|
||||
不管是指导 Agent 的 CLAUDE.md,驱动研究的 program.md,还是被编译成 Wiki 的 raw/ 目录,人和 AI 之间的接口,就是纯文本。
|
||||
|
||||
10
|
||||
|
||||
## 动手试试
|
||||
|
||||
如果你想试试,上手门槛其实不高。
|
||||
|
||||
把 Karpathy 的 gist 内容复制给你的 Agent,然后说:「帮我建一个关于 XX 的 LLM Wiki」。Agent 会帮你创建目录结构、写好配置文件、引导你完成第一次资料灌入。
|
||||
|
||||
Karpathy 推荐了几个工具:
|
||||
|
||||
- **Obsidian** 作为浏览和可视化 Wiki 的 IDE
|
||||
- **Obsidian Web Clipper** 浏览器插件,一键把网页文章转成 Markdown
|
||||
- **qmd** ,一个本地的 Markdown 搜索引擎,支持 BM25 和向量混合搜索,全部在本地运行
|
||||
- **Marp** 插件,直接从 Wiki 内容生成幻灯片
|
||||
- **Dataview** 插件,对页面元数据做查询,生成动态表格
|
||||
|
||||
整个 Wiki 说到底就是一个 Markdown 文件的 Git 仓库,版本历史、分支、协作,全都是现成的。
|
||||
|
||||
**Karpathy 自己也承认,目前这套系统还是「一堆拼凑的脚本」。**
|
||||
|
||||
但他觉得这里面有一个巨大的产品机会,应该有人来把它做成真正好用的产品。
|
||||
|
||||
Yuchen Jin 用 Claude Agent 画了一张架构图来总结这套模式,顺便问了 Karpathy 一个问题:你会开源你自己的个人 LLM Wiki 吗?想象一下,如果牛人们都发布自己的 living wiki,那会是什么样的世界。
|
||||
|
||||
' fill='%23FFFFFF'%3E%3Crect x='249' y='126' width='1' height='1'%3E%3C/rect%3E%3C/g%3E%3C/g%3E%3C/svg%3E)
|
||||
|
||||
Yuchen Jin 用 Claude Agent 生成的 LLM Wiki 架构图
|
||||
|
||||
**人负责选题、判断和思考。**
|
||||
|
||||
**LLM 负责剩下的一切。**
|
||||
|
||||
◇ ◆ ◇
|
||||
|
||||
相关链接:
|
||||
|
||||
<https://gist.github.com/karpathy/442a6bf555914893e9891c11519de94f>
|
||||
|
||||
<https://x.com/karpathy/status/2039805659525644595>
|
||||
|
||||
<https://x.com/karpathy/status/2040470801506541998>
|
||||
|
||||
<https://x.com/FarzaTV/status/2040563939797504467>
|
||||
|
||||
继续滑动看下一个
|
||||
|
||||
AGI Hunt
|
||||
|
||||
向上滑动看下一个
|
||||
|
||||
搜索范围
|
||||
|
||||
全网
|
||||
|
||||
文库
|
||||
|
||||
学术
|
||||
|
||||
所有文献
|
||||
|
||||
所有文献
|
||||
|
||||
中文库
|
||||
|
||||
英文库
|
||||
|
||||
---
|
||||
|
||||
PubMed
|
||||
|
||||
北大核心
|
||||
|
||||
中科院分区
|
||||
|
||||
全部
|
||||
|
||||
---
|
||||
|
||||
中科院1区
|
||||
|
||||
中科院1-2区
|
||||
|
||||
中科院1-3区
|
||||
|
||||
JCR
|
||||
|
||||
全部
|
||||
|
||||
---
|
||||
|
||||
JCR:Q1
|
||||
|
||||
JCR:Q1-Q2
|
||||
|
||||
JCR:Q1-Q3
|
||||
|
||||
SCIE
|
||||
|
||||
EI
|
||||
|
||||
图片
|
||||
|
||||
视频
|
||||
|
||||
播客
|
||||
|
||||
我的
|
||||
|
||||
全部
|
||||
|
||||
我的
|
||||
|
||||
通识-持续更新
|
||||
|
||||
知识库obsidian
|
||||
|
||||
秘塔AI入门精选和使用技巧
|
||||
|
||||
AIforEDU
|
||||
|
||||
AI全栈提示词助手prompt专家
|
||||
|
||||
Download | Tailscale
|
||||
|
||||
营养师
|
||||
|
||||
芯片·半导体 行业全景库(持续更新)
|
||||
|
||||
慢成长图书馆(持续更新)
|
||||
|
||||
心灵工具箱
|
||||
|
||||
强度
|
||||
|
||||
深入
|
||||
|
||||
简洁
|
||||
|
||||
深入
|
||||
|
||||
深度研究
|
||||
|
||||
先想后搜
|
||||
|
||||
先搜后扩
|
||||
|
||||
科技新闻
|
||||
Reference in New Issue
Block a user